2024/10/3大约 12 分钟
02.基础
- 为了能够完成各种数据操作,我们需要某种方法来存储和操作数据。 通常,我们需要做两件重要的事:
- 获取数据
- 将数据读入计算机后对其进行处理。
- 如果没有某种方法来存储数据,那么获取数据是没有意义的
- 许多方法与
Numpy使用相同,但深度学习框架又比Numpy的ndarray多一些重要功能: 首先,GPU很好地支持加速计算,而NumPy仅支持CPU计算;其次,张量类支持自动微分
2.1 基本操作
- 张量表示一个由数值组成的数组,这个数组可能有多个维度
具有一个轴的张量对应数学上的向量(vector);具有两个轴的张量对应数学上的矩阵(matrix);具有两个轴以上的张量没有特殊的数学名称
维度:张量可以具有多个维度, 第一维是最内层的数组,之后逐渐向外增加包裹的数组增加维度
- 对于
reshape()或torch.zeros()来说,维度从高到低传入,最后一个传入的数字才是第一维(最内侧数组) - 对于指定维度的方法如
sum(axis=n)或cat((X, Y), dim=0),axis为0变的是最高维
- 对于
创建张量的方法
torch.arange(12)获得从0开始的前12个数组成的一维向量,默认是整型,可以通过dtype=torch.float64修改或传入浮点类型12.0torch.zeros((2, 3, 4))获得全为0形状为(2,3,4)的三维张量;同样torch.ones((2, 3, 4)),得到的是全为1形状为(2,3,4)的张量torch.randn(3, 4),得到的是形状为(3,4)的张量,其中的每个元素都从均值为0、标准差为1的标准高斯分布(正态分布)中随机采样torch.normal(0, 1, (3, 3))从(0,1)分布中采样现状为(3,3)的张量torch.tensor([[2, 1, 4, 3], [1, 2, 3, 4], [4, 3, 2, 1]])通过数组设置确定值(使用原类型),还有一个大写版本Tensor默认使用float32类型
注意torch.Tensor(4)相对于创建大小为4的随机张量,torch.tensor(4)相对于创建标量tensor(4)
张量常用方法
x.shape得到张量的形状数组,比如(3,4,5)张量得到的是torch.Size([3, 4 , 5]),可以通过索引访问对应的分量大小,而len(x)结果是最高维的大小x.dtpye查看张量存储的数据类型x.numel()得到张量中的元素总数x.reshape(3, 4)将张量转换为形状为(3,4)的张量,允许省略传入一维为-1x.sum()对张量求和降维,可以使用axis指定需要降维的方向,可以使用keepdims=True保持维度不变;求平均x.mean()方法同理x.norm()求范数torch.cat((x, y), dim=0)得到在最高维拼接在一起的新张量(无广播机制,除拼接维度外其他维度形状大小要相同)torch.matmul(x, y)对x和y进行计算,结果和维数有关
维数 (x_dim, y_dim) 结果 限制 结果维度 x_dim=1, y_dim=1 向量点积 x 和 y 的长度必须相同 标量 x_dim=1, y_dim>=2 x作为行向量与y进行矩阵乘法,然后将结果降一维 x的长度必须等于y的次低维 y的次低维被移除后的形状 x_dim>=2, y_dim=1 y作为列向量与x进行矩阵乘法,然后将结果降一维 x的最低维必须等于y的长度 x的最低维被移除后的形状 x_dim>=2, y_dim>=2 最后两维执行标准矩阵乘法,其他维度使用广播 x的最低维必须等于y的次低维,其他维度必须可以广播 广播后的前置批量维度 + 矩阵计算结果维度
2.1.1 运算符
- 运算符运算
x = torch.tensor([1.0, 2, 4, 8])
y = torch.tensor([2, 2, 2, 2])
# 相对于对其中每一位元素进行基本算数运算
x + y, x - y, x * y, x / y, x ** y # **运算符是求幂运算
torch.exp(x) # 求指数幂
# 结果:tensor([2.7183e+00, 7.3891e+00, 5.4598e+01, 2.9810e+03])
# 比较运算符对两张量都有元素的部分每个元素分别比较,生成bool类型张量
# 比如(2, 4)张量和(2, 2)张量生成(2, 2)结果张量
x == y, x >= y, x < y- 广播机制:对于
+-*/操作而言,如果形状不同,有时也可以计算 - 满足广播需要两个张量的每个维度满足以下条件:
- 每个tensor至少有一个维度;
- 遍历tensor所有维度时,从末尾随开始遍历,两个tensor存在下列情况
- 这两个维度的大小相等
- 某个维度 一个张量有,一个张量没有(向外增加维度,使维度相等)
- 某个维度 一个张量有,一个张量也有但大小是1(在本维度进行复制)
- 节省内存:默认的一些运算会使用新内存存储结果,一般情况可能希望进行原地更新。执行原地操作非常简单,我们可以使用切片表示法将操作的结果分配给先前分配的数组
Y[:] = <expression>
# 提前创建空间存储
Z = torch.zeros_like(Y)
print('id(Z):', id(Z))
Z[:] = X + Y
print('id(Z):', id(Z))
# 后续没有使用X
before = id(X)
X += Y # 或 X[:] = X + Y
id(X) == before- 切片与访问
# 通过基本的切片功能,能够方便地获取和修改对应部分的值
# -1选择最后一个低一维数组,[1:3]选择第二个和第三个低一维元素数组
X[-1], X[1:3]
# 多维索引之间通过,分隔,同时允许赋值
X[1, 2] = 92.1.2 与其他python对象转换
# 与numpy互转
A = np.array([[1,2,3],[6,5,3]])
B = torch.tensor(A) # torch.from_numpy(A)
C = B.numpy()
# 对C修改A,B都会相应的改变
C[1] = 0
type(A), type(B)
# 将大小为1张量转换为数字类型(使用内置方法item或使用类型转换)
a = torch.tensor([3.5])
a, a.item(), float(a), int(a)
# 大小不为1转换为列表
x.tolist()2.2 数据预处理
- 使用
panda库读取csv文件并处理缺失值 panda可以使用to_numpy方法转换为numpy再与torch转换
2.3 线性代数
- 就像向量是标量的推广,矩阵是向量的推广一样,我们可以构建具有更多轴的数据结构。张量是描述具有任意数量轴的
n维数组的通用方法
2.3.1 矩阵运算
Hadamard积,即A * B- 两个一维向量点积,即
torch.dot(x, y) - 矩阵向量积,矩阵和向量做矩阵乘法,即
torch.mv(A, x),矩阵A可以看成多个行向量因此相对于是多次点积 - 矩阵乘法,即
torch.mm(A, B)(仅支持二维及以下,高维请使用torch.matmul(A, B))
2.3.2 范数
- 在机器学习和数据科学中,范数常常被用来作为正则化项,防止模型过拟合,或者用来衡量模型复杂度
- 具体来说,范数(
Norm)是一种测量向量“长度”或“大小”的函数。范数需要满足一些性质,包括:- 非负性:对任意向量v,范数都是非负的,即,且当且仅当时,
- 一致性:对任意标量a和任意向量v,有
- 三角不等式:对任意向量u和v,有
- 范数
- 范数:向量中所有数的绝对值之和
- 范数:向量中所有数的平方之和开根号,范数表示中的2可以省略
- 范数:上面两种范数的泛化
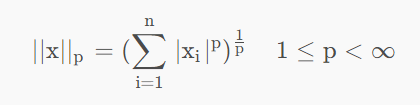
# 计算矩阵范数(支持1/2/无穷L范数),默认为2范数
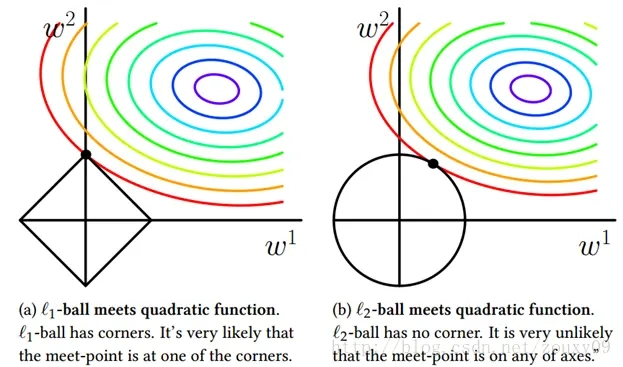
torch.linalg.norm(x, ord=torch.inf) # equals to x.norm(ord=torch.inf)- 对于仅有两个元素的一维向量,可以画出对应的范数图像,对于一个二维的范数图像来看,p越大,范数图像越呈现正方形,L1范数是菱形,L2范数是圆形

- 在深度学习/机器学习中,Lp范数往往是作为一个正则化项加在损失函数的后面用以优化参数,L1(黑色菱形)与参数权重(彩色等高线)相交之处多是在坐标轴上,所以多产生稀疏矩阵;L2范数(黑色圆形)与参数矩阵多相交在较低值参数区域,所以能防止一些较大参数的产生,平滑的优化参数
2.4 微积分
- 在深度学习中,我们“训练”模型,不断更新它们,使它们在看到越来越多的数据时变得越来越好
- 通常情况下,变得更好意味着最小化一个损失函数(loss function),即一个衡量“模型有多糟糕”这个问题的分数
- 最终,我们真正关心的是生成一个模型,它能够在从未见过的数据上表现良好。但“训练”模型只能将模型与我们实际能看到的数据相拟合
- 因此,我们可以将拟合模型的任务分解为两个关键问题:
- 优化(optimization):用模型拟合观测数据的过程;
- 泛化(generalization):数学原理和实践者的智慧,能够指导我们生成出有效性超出用于训练的数据集本身的模型
2.4.1 导数、微分和梯度
- 对于一个标量方程(输出是标量)而言,求导数、微分可以使用下列公式
- 导数: 对于标量函数,其导数公式为:
- 偏导数:对于标量函数,其对第个变量的偏导数公式为:
- 微分: 对于标量函数,其微分公式为:
- 梯度:对于标量函数,其梯度公式为:
2.4.2 向量方程求导和梯度
- 向量方程指的是输入或输出结果为向量的方程,比如或,设函数的输入是一个n维向量,有
- 向量方程计算的分子布局和分母布局:向量方程组计算过程中遇到求偏导时,会将向量扩展成矩阵,由于矩阵未规定如何扩展,存在两种扩展方法
- 分子布局:行数与分子向量的行数一致,即先确定每行对应一个向量方程,每列是对一个变量求得的偏导
- 分母布局:行数与分母(输入)的行数一致,即先确定每行对应一个输入分量,每列是对一个向量方程求偏导
- 向量方程梯度有以下性质(分母布局),是的矩阵,是维列向量
2.5 自动微分
- 深度学习框架通过自动计算导数,即自动微分(automatic differentiation)来加快求导
# 开启自动求梯度功能,要求使用浮点类型
x=torch.arange(4.0,requires_grad=True) # or x.requires_grad_(True)
# 自动微分是针对标量来做的,即backward仅支持对大小为1的结果
# 因此有时需要利用线性组合的方式将结果结合在一起,比如sum方法
y = 2 * x
y.sum().backward()
# 或在backward传入一个向量,用来表示线性组合
# 相当于求A = 2*(x_1 + x_2 + x_3 + x_4)的梯度
y.backward(torch.tensor([1, 1, 1, 1]))
# 梯度结果
x.grad
# 清空之前梯度计算结果
x.grad.zero_()- 对于复杂梯度的例子
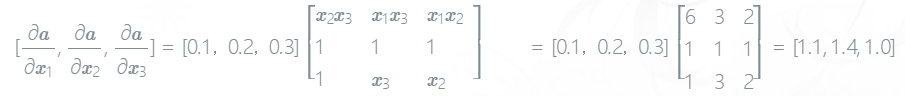
x1 = torch.tensor(1, requires_grad=True, dtype=torch.float)
x2 = torch.tensor(2, requires_grad=True, dtype=torch.float)
x3 = torch.tensor(3, requires_grad=True, dtype=torch.float)
y = torch.randn(3)
y[0] = x1 * x2 * x3
y[1] = x1 + x2 + x3
y[2] = x1 + x2 * x3
A = 0.1 * y[0] + 0.2 * y[1] + 0.3 * y[2]
# y.backward(torch.tensor([0.1, 0.2, 0.3], dtype=torch.float))
A.backward()
print(x1.grad)
print(x2.grad)
print(x3.grad)
'''
res:
tensor(1.1000)
tensor(1.4000)
tensor(1.)
'''需要注意的是,如果需要计算其他数学公式,请使用torch中的版本,才能使用自动微分
- 分离计算:有时可能希望将部分带参部分暂时忽略,比如:,其中的,我们可能只希望得知外侧的的一些信息,而暂时将当做常数
x.grad.zero_()
y = x * x
# 实现分离
u = y.detach()
z = u * x
z.sum().backward()
x.grad == u- 对控制流求自动微分
def f(a):
b = a * 2
while b.norm() < 1000:
b = b * 2
if b.sum() > 0:
c = b
else:
c = 100 * b
return c
a = torch.randn(size=(), requires_grad=True)
# f(x)虽然是分段的,但在每个范围都是线性的
d = f(a)
d.backward()
a.grad == d / a2.6 概率
- 机器学习是做出预测,为此需要使用到部分概率相关的内容
2.6.1 单随机变量
- 多项分布,可以通过代码模拟随机抽样
from torch.distributions import multinomial
fair_probs = torch.ones([6]) / 6
multinomial.Multinomial(100, fair_probs).sample()2.6.2 多随机变量贝叶斯定理
2.6.3 期望与方差
