2025/6/11大约 6 分钟
02.基本操作
2.1 常用操作
Redis中默认有16个数据库,可以通过select [0-15]选择数据库- 创建的数据库数量可以在
config文件中database项修改
- 创建的数据库数量可以在
创建和获取数据
# 设置值 set mykey "Hello World" # 获取值,key 区分大小写,如果不存在,返回nil get mykey # Hello World帮助命令
help @类型可以查看对应类型的所有方法,比如help @string
2.2 键相关
| 命令 | 描述 | 示例 |
|---|---|---|
del key [key ...] | 删除一个或多个键 | del key1 key2 |
unlink key [key ...] | 异步删除一个或多个键,仅先在Keyspace元数据中删除 | unlink key1 key2 |
exists key [key ...] | 检查键是否存在,返回存在的个数 | exists mykey |
expire key seconds | 设置键的过期时间(s) | expire mykey 60 |
expireat key timestamp | 在指定时间戳使键过期(s) | expireat mykey 1728000000 |
ttl key | 返回键的剩余生存时间(s),-1表示永不过期,-2表示已过期 | ttl mykey |
pttl key | 返回键的剩余生存时间(ms) | pttl mykey |
persist key | 移除键的过期时间,使其永久有效 | persist mykey |
rename key newkey | 重命名键(若存在将覆盖) | rename old new |
renamenx key newkey | 重命名键(仅当键不存在时) | renamenx old new |
move key db | 将键移动到指定数据库中 | move mykey 1 |
type key | 返回键存储的值的数据类型 | type mykey |
keys pattern | 查找所有匹配给定模式的键 | keys user:* |
scan cursor [match pattern] [count count] | 增量迭代键 | scan 0 match user:* count 100 |
randomkey | 随机返回当前数据库中的一个键 | randomkey |
dump key | 序列化键的值(用于迁移) | dump mykey |
restore key ttl serialized-value | 反序列化并恢复键 | restore mykey 0 "serialized-value" |
sort key [by pattern] [get pattern] ... | 对列表、集合或有序集合排序 | sort mylist |
object [subcommand] key | 查看键的内部信息,如引用计数、编码等 | object encoding mykey |
dbsize | 返回当前数据库的键数 | dbsize |
flushdb | 清空当前数据库的所有键 | flushdb |
flushall | 清空所有数据库的所有键 | flushall |
一般非查询命令,返回数字0表示失败,返回1表示成功,像
del返回的是删除数据的条数;查询命令返回的数字1表示存在,0表示不存在
2.3 数据类型对应操作
redis是k-v数据库,其中的键的类型都是字符串,值的类型可以是下列数据类型,即String、Bitmap、Bitfield、Hash、List、Set、Sorted set、Stream、Geo、HyperLog
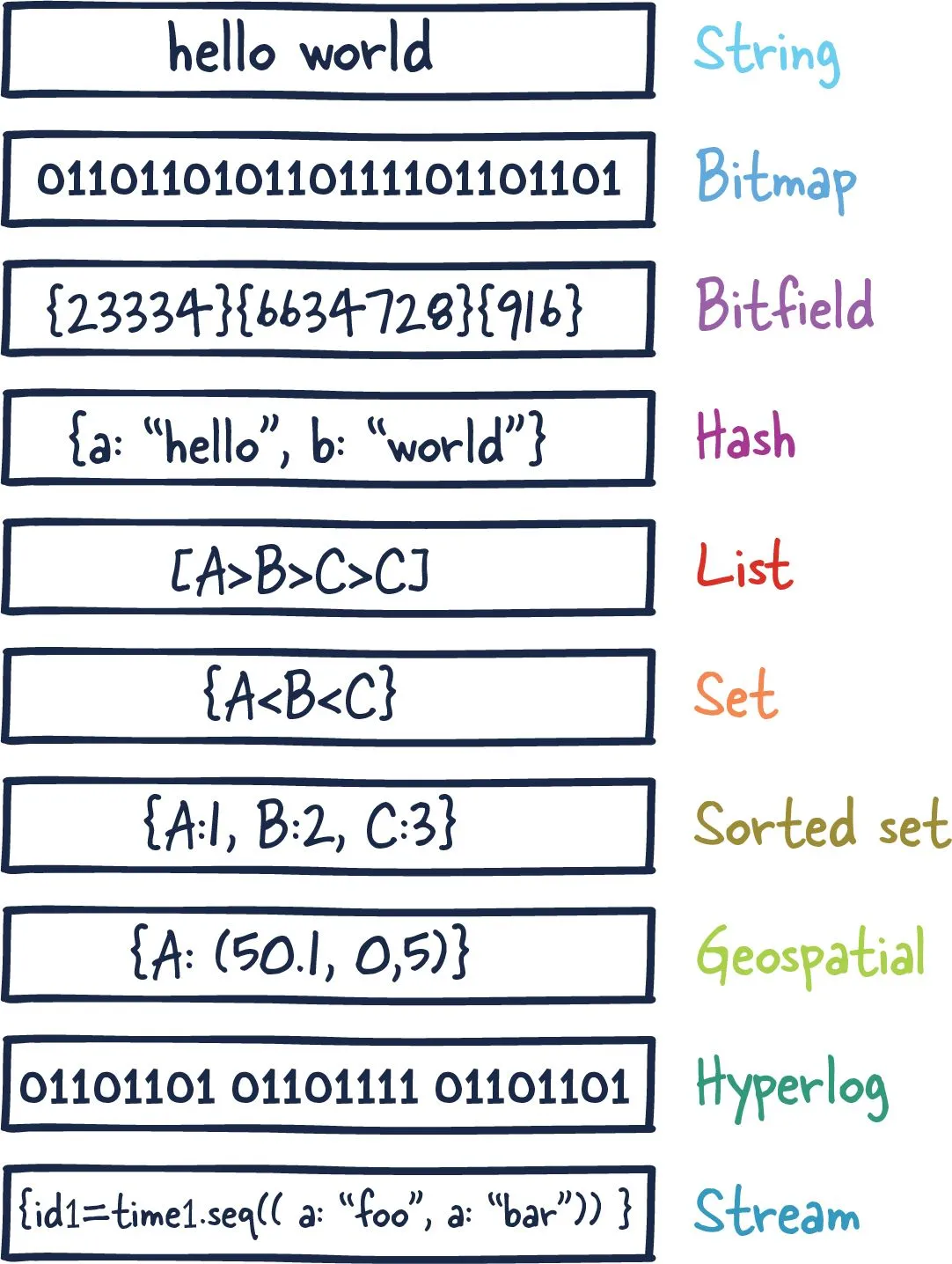
2.3.1 字符串String
- string是redis最基本的类型,一个key对应一个value
- string类型是二进制安全的,意思是redis的string可以包含任何数据,比如jpg图片或者序列化的对象
- string类型是Redis最基本的数据类型,一个redis中字符串value最多可以是512M
2.3.2 位图Bitmap
- 使用0和1的二进制位数组
2.3.3 位域Bitfield
- 通过bitfield命令可以一次性操作多个比特位域(指的是连续的多比特位),它会执行一系列操作并返回一个响应数组,这个数组中的元素对应参数列表中的相应操作的执行结果
- 说白了就是通过bitfield命令我们可以一次性对多个比特位域进行操作
2.3.4 哈希表Hash
- hash是一个string类型的field(字段)和value(值)的映射表,hash特别适合用于存储对象。
- Redis中每个hash可以存储键值对(40多亿)
2.3.5 列表List
- Rdis列表是简单的字符串列表,按照插入顺序排序。你可以添加一个元素到列表的头部(左边)或者尾部(右边)
- 它的底层实际是个双端链表,最多可以包含个元素(4294967295,每个列表超过40亿个元素)
2.3.6 无序集合Set
- Redis的Set是String类型的无序集合。
- 集合成员是唯一的,这就意味着集合中不能出现重复的数据,集合对象的编码可以是intset或者
- hashtable。
- Redis中Set集合是通过哈希表实现的,所以添加,删除,查找的复杂度都是O(1)。
- 集合中最大的成员数为2^32-1(4294967295,每个集合可存储40多亿个成员)
2.3.7 有序集合ZSet
- zset(sorted set:有序集合)
- Redis zset和set一样也是string类型元素的集合,且不允许重复的成员。
- 不同的是每个元素都会关联一个double类型的分数,redis正是通过分数来为集合中的成员进行从小到大的排序。
- set的成员是唯一的,但分数(score)却可以重复。
- Zst集合是通过哈希表实现的,所以添加,删除,查找的复杂度都是O(1)。集合中最大的成员数为2^32-1
2.3.8 地理空间Geo
- Redis GEO主要用于存储地理位置信息,并对存储的信息进行操作,包括
- 添加地理位置的坐标
- 获取地理位置的坐标
- 计算两个位置之间的距离
- 根据用户给定的经纬度坐标来获取指定范围内的地理位置集合
2.3.9 基数统计HyperLog
- HyperLogLog是用来做基数统计的算法,HyperLogLog的优点是,在输入元素的数量或者体积非常非常大时,计算基数所需的空间总是固定且是很小的
- 在Redis里面,每个HyperLogLog键只需要花费12KB内存,就可以计算接近个不同元素的基数。这和计算基数时,元素越多耗费内存
- 就越多的集合形成鲜明对比
- 但是,因为HyperLogLog只会根据输入元素来计算基数,而不会储存输入元素本身,所以HyperLogLog不能像集合那样,返回输入的各个元素
2.3.10 流Stream
- Redis Stream是Redis5.0版本新增加的数据结构
- Redis Stream主要用于消息队列(MQ,Message Queue),Redis本身是有一个Redis发布订阅(pub/sub)来实现消息队列的功能,但它有个缺点就是消息无法持久化,如果出现网络断开、Redis宕机等,消息就会被丢弃
- 简单来说发布订阅(pub/Sub)可以分发消息,但无法记录历史消息
- 而Redis Stream提供了消息的持久化和主备复制功能,可以让任何客户端访问任何时刻的数据,并且能记住每一个客户端的访问位置,还能保证消息不丢失